Quando il matematico Nassim Nicholas Taleb nel 2007 scrisse “Il Cigno Nero”, pubblicato in Italia nel 2008, non pensava certo ai piani di Business Continuity (BC) e Disaster Recovery (DR). Il saggio filosofico di Taleb affronta il tema dell’imprevisto, dell’evento inaspettato che cambia improvvisamente le condizioni e le certezze che l’uomo ha consolidato nel tempo.
L’ attentato al World Trade Center nel 2001, l’ attentato del 13 novembre al Bataclan a Parigi e la pandemia da COVID-19 ne sono un chiaro esempio, hanno cambiato improvvisamente e radicalmente le abitudini e la vita delle persone, il loro modo di lavorare, il loro modo di viaggiare, di studiare e socializzare.
Per quanto dopo fatti di questa potenza con il tempo si possa ritornare a condizioni di normalità, sarà una normalità intimamente mutata nelle abitudini come nei nuovi timori.
I lunghi controlli di sicurezza in aeroporto sono un evidente esempio di questa nuova normalità, Raramente si associano alle lunghe trafile dei controlli di sicurezza a cui siamo sottoposti ai fatti che li hanno prodotti.
Quanto accaduto nel 2001 a New York ha interessato anche il mondo delle reti e dei data center. Ritornando a quei giorni ricordiamo infatti che i collegamenti Internet con gli Stati Uniti sono stati interrotti per diversi giorni. La gravità e le dimensioni del disastro avvenuto nel cuore di Manhattan hanno chiaramente fatto passare in secondo piano i problemi occorsi ai collegamenti Internet, tuttavia anche questi, seppure in modo secondario, hanno contribuito a produrre altri gravi danni ad aziende e persone.
Buona parte dei problemi di raggiungibilità Internet degli Stati Uniti sono stati causati dai danni prodotti dal crollo delle Torri Gemelle.
Il PoP di accesso dei collegamenti transatlantici era infatti posto in una delle Torri e la ridondanza era garantita da una struttura analoga situata nell’altra Torre.
Una configurazione che oggi può sembrare ingenua e insufficiente, ma all’epoca il concetto di ridondanza era differente da quello che abbiamo maturato nel corso di questi anni, in buona parte proprio per via di quanto accaduto nel settembre 2001.
Quanto occorso a New York venti anni fa ha cambiato radicalmente l’approccio alla resilienza e alle logiche di Disaster Recovery nonché alla sicurezza a tutto tondo. Come dicevamo gli aereoporti sono senza dubbio gli esempi più evidenti dei cambiamenti avvenuti, tuttavia molti altri aspetti sono cambiati nell’ordinaria sicurezza degli Stati Uniti. Un Paese che ha culturalmente una forte fiducia nel cittadino e nelle sue dichiarazioni. Una caratteristica per altro tipicamente anglosassone.
L’ effetto di tutto questo sui piani di Business Continuity e Disaster Recovery è stato importante. Da allora si è iniziato a prevedere distanze molto importanti tra il sito principale e quello di recovery, ponendo addirittura il sito principale e quello di recovery sulle due coste oceaniche degli Stati Uniti. Un bel salto dal concetto di ridondanza precedente.
Ma definiamo subito il significato di Business Continuity, o Continuità Operativa, e Disaster Recovery. La Business Continuity si riferisce a situazioni in cui l’infrastruttura rimane intatta, ma subentra una variabile che impedisce ai propri dipendenti di lavorare normalmente.
Bufere di neve, uragani, alluvioni, sono buoni esempi, ma ci sono molte altre ragioni per cui un’interruzione potrebbe costringere i dipendenti a rimanere a casa. Se un’azienda utilizza desktop tradizionali accessibili solo dall’ufficio ad esempio, un’interruzione di questo tipo potrebbe essere disastrosa.
Il Disaster Recovery entra in azione a seguito di un evento inaspettato che colpisce l’infrastruttura. Un evento naturale che distrugge un data center o una grave problema di alimentazione elettrica ad esempio.
In uno scenario di Disaster Recovery è probabile che sia necessario che i carichi di lavoro vengano spostati rapidamente in un altro luogo.
La criticità dei servizi e dei collegamenti digitali è definitivamente fuori discussione in quanto ogni tipologia di servizio, anche quando erogato in modalità analogica, ha una componente digitale. A volte può essere digitale solo il back-office, cioè la parte nascosta al fruitore, ma è ormai quasi impossibile individuare servizi che almeno in qualche punto del processo non sfruttino le tecnologie informatiche. Le infrastrutture, i sistemi e le procedure che li erogano devono perciò osservare anche criteri di continuità del servizio adottando misure, architetture, soluzioni e procedure adeguate.
Crite ri normati per legge ad esempio per gli Istituti Bancari e per la Pubblica Amministrazione (PA).
ri normati per legge ad esempio per gli Istituti Bancari e per la Pubblica Amministrazione (PA).
Nel 2011 la PA avviò questo processo di adeguamento con l’introduzione dell’articolo 50bis del Codice dell’Amministrazione Digitale (CAD), prima con la predisposizione di Studi di Fattibilità seguiti poi dai Piani Operativi. La continuità dei sistemi informativi rappresenta infatti per le pubbliche amministrazioni, nell’ambito delle politiche generali per la continuità operativa dell’ente, un aspetto essenziale per l’erogazione dei servizi a cittadini e imprese. Diviene perciò uno strumento utile per assicurare e garantire il corretto svolgimento della vita nel Paese. Nondimeno le organizzazioni private rispondono alla necessità di reagire a situazioni di emergenza da cui dipende, nel peggiore dei casi, la loro stessa esistenza. Ed ecco che i piani di Business Continuity e Disaster Recovery assumono l’importanza che meritano.

Fig. 1 – Definizioni di Business Continuity e Disaster Recovery
L’ evoluzione delle logiche di recovery sono state assecondate dalla crescente diffusione di reti informatiche sempre più capaci e soluzioni tecnologiche avanzate come la virtualizzazione, l’iperconvergenza ed il cloud, tuttavia i grandi promotori sono stati quelli che Taleb ch iama “Il Cigno Nero“ ed ecco che nel 2020 un nuovo Cigno Nero globale, la pandemia da COVID-19.
iama “Il Cigno Nero“ ed ecco che nel 2020 un nuovo Cigno Nero globale, la pandemia da COVID-19.
La Pandemia sanitaria ha colpito progressivamente tutto i paesi della terra e, come accaduto nel 2001, ha riscritto le regole dei piani di Continuità Operativa e Disaster Recovery.
I dipartimenti IT di ogni azienda hanno dovuto predisporre sistemi per l’accesso sicuro alle reti aziendali, strumenti per la condivisione dei dati e soluzioni per l’uso di applicativi aziendali al di fuori del perimetro di sicurezza della rete locale.
Tutte le attività aziendali dovevano essere svolte prevalentemente da dipendenti fuori sede.
Servizi per certi versi relativamente semplici, spesso già esistenti per un numero molto limitato di utenti, ma non sempre pronti a scalare fino all’80% e oltre dei dipendenti.
Cyber Security e processi interni sono stati interessati da cambiamenti importanti e repentini. Non solo si è dovuto rispondere ad un nuovo modello operativo ma alcuni servizi sono stati sottoposti a sollecitazioni straordinarie. Basti pensare all’e-commerce che ha consentito ad esempio di acquistare libri, quaderni, materiale scolastico nei lunghi mesi di rigido lockdown durante i quali tutti i punti vendita sono stati chiusi.
Come accaduto per gli eventi del recente passato anche la Pandemia da COVID-19 ha introdotto nuovi scenari nei piani di continuità operativa e disaster recovery. I piani di BC/DR non sono solo documenti formali ma devono rispondere in modo pratico ad una serie di condizioni identificate come potenzialmente critiche, sia dal punto di vista organizzativo che tecnico.

Fig. 2 – Definizioni di Business Continuity e Disaster Recovery Schema flusso piano di BC/DR
L’esperienza vissuta a partire dai primi mesi del 2020 ha messo in evidenza come anche solo la gestione sicura delle credenziali dei sistemi, se non prevista, pianificata e coordinata opportunamente, può presentare molti più problemi di quanto si possa immaginare.
E’ indubbio che la definizione dei piani di Business Continuity e Disaster Recovery richiedono un certo impegno di risorse e un’organizzazione adatta a rispondere adeguatamente in condizioni di emergenza. Dal punto di vista organizzativo occorre identificare un Comitato di Crisi che ha la funzione di governare le situazioni di emergenza ed è normalmente costituito da alti livelli manageriali affiancati dal responsabile della Continuità Operativa. Quest’ultimo ha anche la funzione di raccordo con i livelli manageriali intermedi e con il Team di Recovery.
Il Team di Recovery a sua volta è costituito da esperti e tecnici operativi incaricati di eseguire le procedure tecniche previste.
Il Comitato di Crisi, una volta avviata l’emergenza, ha il compito di valutare la reazione in modo proporzionale all’accaduto, deve cioè decidere se applicare integralmente le procedure previste dal piano o intervenire in modo parziale. Le decisioni del Comitato di Crisi devono essere poi trasmesse al Team di Recovery che ha il compito di avviare il ripristino dei servizi nel sito remoto seguendo le procedure previste.
In sintesi i passi da seguire nel caso di un’emergenza possono essere:
-
Segnalazione dell’emergenza
-
Valutazione delle criticità
-
Attivazione del Comitato di Crisi
-
Gestione dell’emergenza e innesco piano di DR
-
Attivazione del Team di Recovery
-
Avvio attività tecniche
Ogni punto riportato nell’elenco di esempio, dovrebbe essere alimentato da specifiche procedure operative e da tutte le informazioni necessarie a svolgere il flusso di azioni previste. Ad esempio il Comitato di Crisi dovrebbe avere a disposizione l’elenco dei componenti del Team di Recovery e di tutti i riferimenti necessari per contattarli. Semplice ma non scontato.

Una volta superata la fase di emergenza lo stesso Comitato di Crisi dovrebbe gestire il rientro alla normalità e avviare sempre tramite il Team di Recovery le procedure di ripristino del sito principale.
L’ambito in cui si devono muovere Comitato di Crisi e il Team di Recovery deve essere chiaro, circoscritto e ben definito. I servizi digitali sono moltissimi e prevedere un ripristino su un sito secondario di tutti i servizi erogati può essere molto oneroso e non particolarmente utile.
Prima della definizione del piano è infatti necessario rispondere a diverse domande, come ad esempio quali servizi sono vitali per la nostra organizzazione, quali servizi in condizioni di emergenza possono essere temporaneamente sospesi e quale può essere l’impatto della loro sospensione, tra le altre cose è anche necessario valutare se è accettabile una perdita di dati e in quale misura.
Valutazioni non semplici. Gli effetti di una situazione di emergenza possono non essere immediati da individuare e classificare ed è per questo che entrano in gioco il Recovery Point Objective (RPO) e il Recovery Time Objective (RTO), parametri che devono essere preventivamente quantificati e che rispondono in parte alle domande precedenti. Il Recovery Point Objective (RPO) infatti definisce la perdita di dati ammissibile. Ad esempio, si possono presentare situazioni in cui può essere sufficiente ripristinare i dati da un backup per minimizzare l’impatto dell’incidente e quindi la perdita di dati ammissibile può essere quella recuperabile dall’ultimo backup.

Il Recovery Time Objective (RTO) utilizza invece il tempo come elemento decisionale. In pratica individua quanto tempo un servizio può rimane indisponibile prima dell’insorgere di gravi problemi alle attività o all’immagine dell’azienda. Naturalmente sia l’RPO che l’RTO cambiano a seconda della natura e caratteristiche dell’organizzazione e dello specifico servizio esaminato.
Criticità dei servizi e parametri quali RPO e RTO sono valutazioni che possono emergere da un’attività di analisi come la Business Impact Analysis (BIA). La BIA consiste in una serie di interviste svolte sulla base di un template ai Responsabili e al personale delle Aree Funzionali ritenute critiche. In questa fase emergono autovalutazioni, collegamenti e dipendenze tra servizi e aree che vengono registrate e poi rielaborate, ed infine mediate per equilibrare le diverse valutazioni e fornire un quadro completo utile ad alimentare il piano di DR.
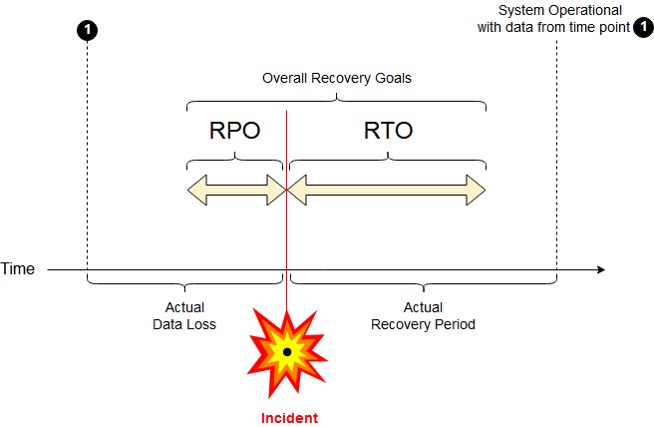
Fig. 3 – Rappresentazione schematica dei parametri RPO ed RTO. In questo caso i valori attesi non sono pienamente rispettati. (Fonte Wikipedia)